
Blending visual and textual concepts into a new visual concept is a unique and powerful trait of human beings that can fuel creativity. However, in practice, cross-modal conceptual blending for humans is prone to cognitive biases, like design fixation, which leads to local minima in the design space. In this paper, we propose a T2I diffusion adapter "IT-Blender" that can automate the blending process to enhance human creativity. Prior works related to cross-modal conceptual blending are limited in encoding a real image without loss of details or in disentangling the image and text inputs. To address these gaps, IT-Blender leverages pretrained diffusion models (SD and FLUX) to blend the latent representations of a clean reference image with those of the noisy generated image. Combined with our novel blended attention, IT-Blender encodes the real reference image without loss of details and blends the visual concept with the object specified by the text in a disentangled way. Our experiment results show that IT-Blender outperforms the baselines by a large margin in blending visual and textual concepts, shedding light on the new application of image generative models to augment human creativity.
IT-Blender is a T2I diffusion adapter that can automate the blending process of visual and textual concepts to enhance human creativity.
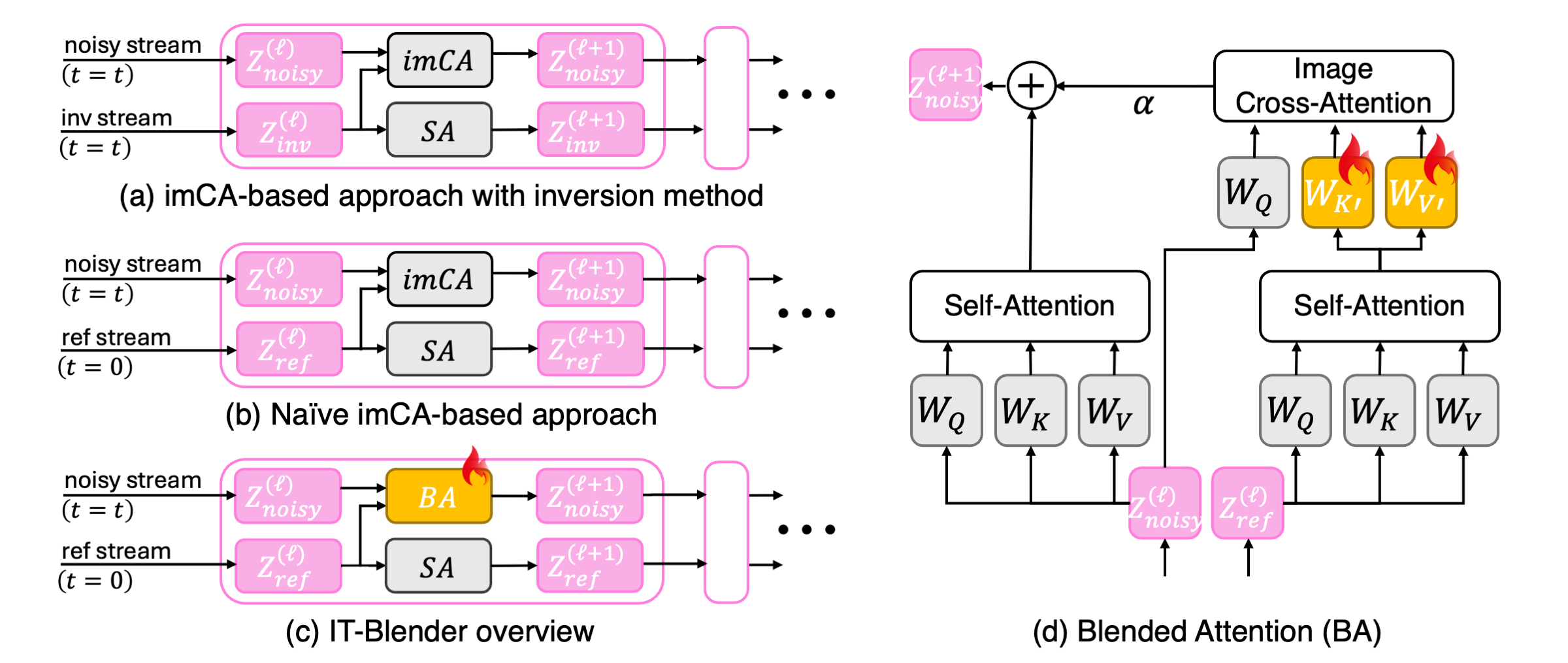
(a) Image Cross-Attention (imCA) approach with inversion method. They have advantages
in applying the details of the visual concepts in a disentangled manner,
while the performance is degraded when real images are given as input due to the distribution shift of the inversion chain.
(b) Naïve imCA-based approach without inversion method. Potentially better encodes the details of the clean image rather
than noisy images as in inversion-based methods. The performance would
be poor because of a significant distribution shift; the reference latents are from a clean image with
t = 0 while the noisy latents are from noisy images with a t ≥ 0.
(c) IT-Blender. Can bridge the distributional gap between the noisy stream and the clean reference stream by learning how to map the clean
latent (Z_ref) to the noisy latent (Z_noisy) in the projection space. The standard denoising objective is used for both StableDiffusion and FLUX. The comparison between (b) and (c) are provided below.

(d) Blended Attention. The branch on the left is the original pretrained
self-attention module, which can keep the estimation on
the original trajectory. The second branch connected to imCA on the right is the key to blended attention, which
dynamically aligns SA(Z_noisy) and SA(Z_ref) in the output space of Self-Attention to fetch the useful visual concepts from the
reference stream, driven by the query from the noisy stream. The equation is as follows:
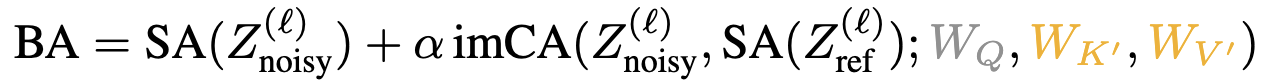
Baseline comparisons with StableDiffusion 1.5
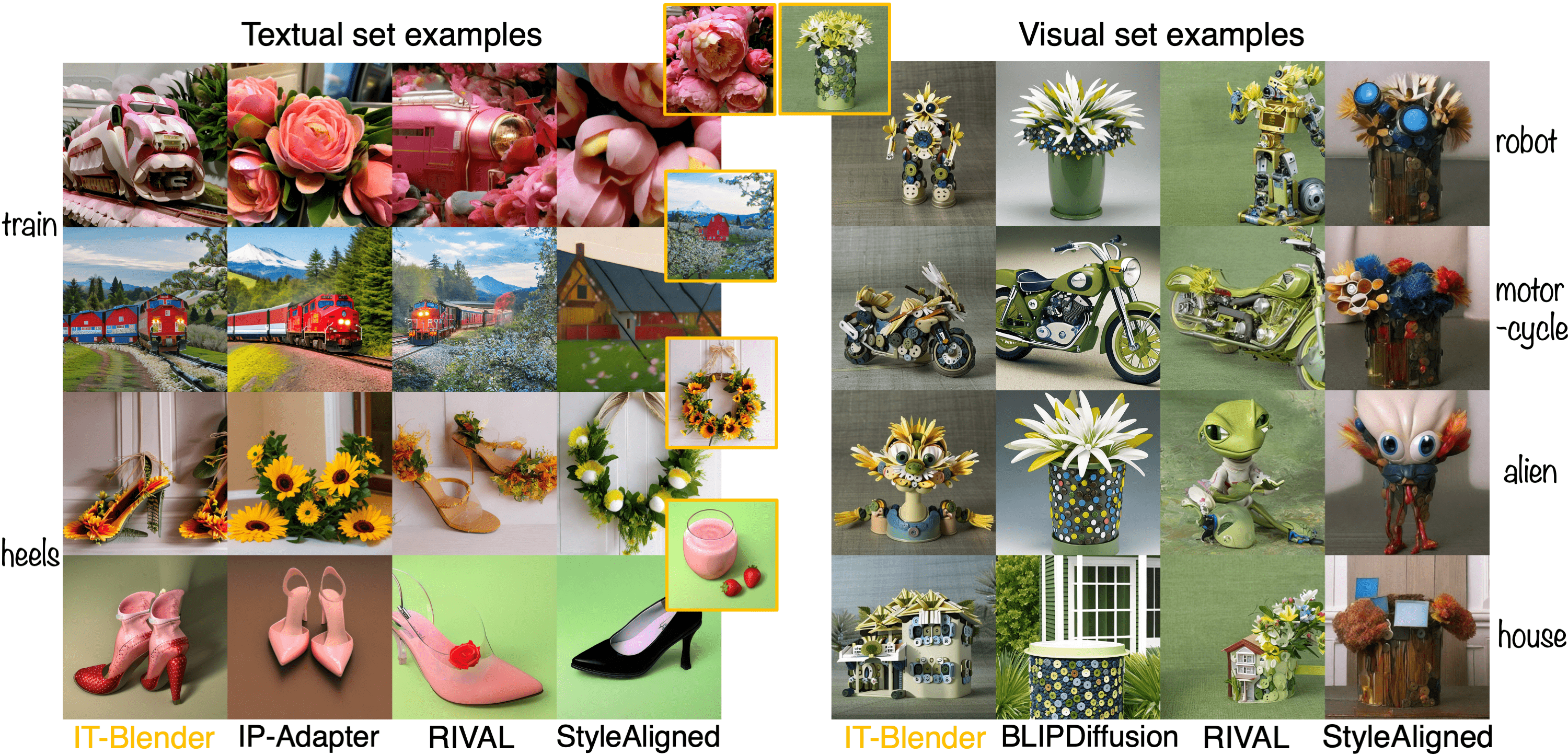
Baseline comparisons with FLUX.1-dev













Positive societal impact. IT-Blender can augment human creativity, especially for people in creative
industries, e.g., design and marketing. With IT-Blender, designers might be able to have better final
design outcome by exploring wide design space in the ideation stage.
Negative societal impact. IT-Blender can be used to apply the
design of an existing product to the new products. The user must be aware of the fact that they can
infringe on the company’s intellectual property if a specific texture pattern or material combination is
registered. We encourage users to use IT-Blender to augment creativity in the ideation stage, rather
than directly having a final design outcome.
@article{cho2025imagine,
title={Imagine for Me: Creative Conceptual Blending of Real Images and Text via Blended Attention},
author={Cho, Wonwoong and Zhang, Yanxia and Chen, Yan-Ying and Inouye, David I},
journal={arXiv preprint arXiv:2506.24085},
year={2025}
}